พอดีได้ข่าวว่า Final Fantasy X ได้ทำการ Port มาลง PC ก็เลยลองเล่นดูครับ เพราะภาคนี้ผมเล่นตอน PS2 ได้ประมาณ 30-40% แล้วก็ไม่ได้เล่นต่อเนื่องจากติดทำ Project จบสมัยเรียน เลยขายเครื่องทิ้งไปเพราะกลัวเรียนไม่จบ 🙂
แต่ที่เขียนถึงวันนี้คงพูดถึงเรื่อง Windows architecture กันนิดหน่อย
สืบเนื่องมาจากว่า ผมเล่นเกมนี้ไปได้ประมาณไม่นานเช่น 10-20นาที โปรแกรมก็ Crash ซึ่งมาจากขั้นตอนที่ไม่แน่นอน หรือเรียกว่า Random Crash นั่นเอง
ซึ่งการ Crash ของ Application นั้นก็หมายถึงการที่โปรแกรมหยุดทำงานด้วยสาเหตุใดสาเหตุหนึ่งแล้วโปรแกรมก็เด้งออกอัตโนมัติทิ้งให้เราอึ้งไปหลายวิ..
As User
จากการที่เราเป็น End User ของเกมนี้ก็ แน่นอนครับ ติดปัญหาเราก็ต้องลองหาใน Google ดูก็ก่อนเลย ซึ่งก็พบว่ามีหลายๆคนเจอปัญหาเดียวกัน
http://steamcommunity.com/app/359870/discussions/0/364042063114641626/
http://steamcommunity.com/app/359870/discussions/0/364042262885080038/
http://steamcommunity.com/app/359870/discussions/0/364042262879682906/
ซึ่งผมลองทำตาม workaround ต่างๆแต่ก็ยังไม่สำเร็จ เล่นไปสักแป๊บนึงเกมก็เด้งออกมาอีกเช่นเคย
As Developer
แต่ด้วยความที่เราก็ Developer ผมก็ตัดสินใจลอง Investigate ปัญหานี้ดูด้วยตัวเอง
สิ่งแรกที่ผมเห็นคือเวลามัน Crash ตัวไฟล์ CoreDump.dmp จะถูกสร้างขึ้นมา
ลองเปิดด้วย Visual Studio เพื่อทำการ Analyze Dump ไฟล์ได้ข้อมูลน่าสนใจตามนี้
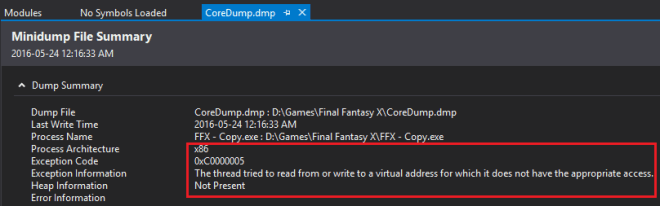
- Process นี้เป็น x86 ก็คือ 32 Bits
- Crash ที่เกิดขึ้นมี Exception เกี่ยวกับ Virtual Address หรือ Virtual Memory นั่นเอง
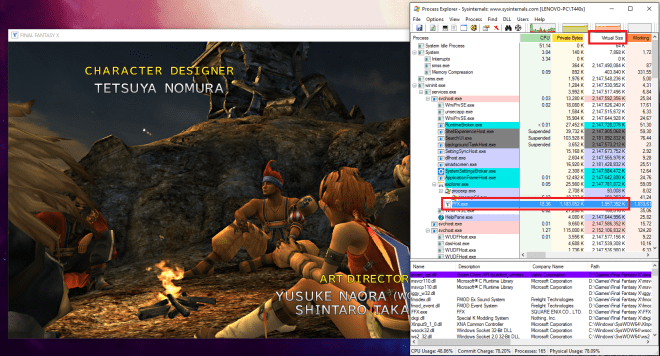
พอรู้แบบนี้ผมก็ลองเปิด Process Explorer ดูเลยครับว่าเวลาเล่นเกมนี้ มันใช้ Memory ขนาดไหน ปรากฎว่า…
ชัดเจนครับแค่เปิดเกมมา Virtual Memory ก็1.9GB แล้ว
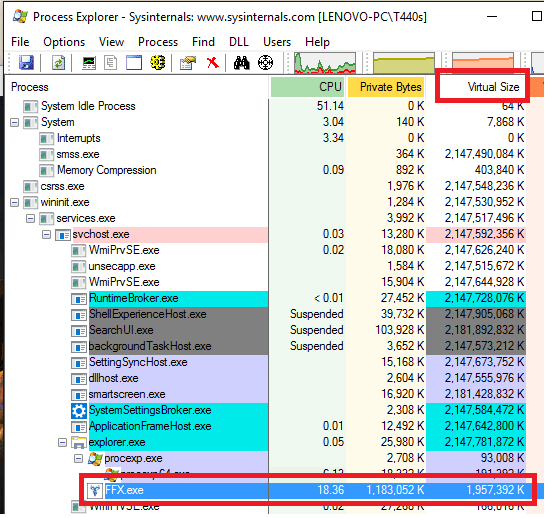
นี่คือสาเหตุของปัญหานี้ครับ..เนื่องจากว่า เกม(Process) นี้ถูก Compile ด้วย 32 Bits ทำให้สามารถใช้งาน Memory Space ได้ 2^32 bytes หรือประมาณคร่าวๆได้ 4GB (4,000,000KB โดยประมาณ)
แต่เนื่องจาก Windows Architect นั้นได้ทำการแบ่ง Memory ไว้เป็น 2 ส่วนคือ Kernel space กับ Application space (User space) อย่างละ 2GB
ซึ่งง่ายๆก็คือ Applicatoin จะใช้ได้ 2GB เท่านั้น ทำให้ถ้าใช้เกินโปรแกรมก็จะ Crash (ถ้าจัดการไม่ดี)
วิธีแก้ปัญหา
Windows นั้นได้มี Feature ที่เรียกว่า Large Address Aware ซึ่งทำให้ Application สามารถใช้งาน Memory ได้มากกว่า 2GB นั่นเอง
Tool ตัวนี้คือ Editbin.exe ซึ่งติดตั้งมากับ Microsoft Visual Studio อยู่แล้วครับ
พิมพ์ไปเลยครับตามนนี้
editbin /largeaddressaware “D:\Games\Final Fantasy X\FFX.exe”
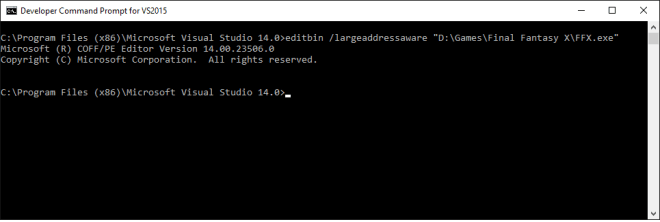
เราก็จะได้ FFX.exe ตัวใหม่ที่ทำการเปิด Feature Large Address Aware แล้ว และเมื่อลองทดสอบดู Process ของเกมนี้ก็สามารถใช้ Memory ได้เกิน 2GB แล้ว

และสุดท้ายตั้งแต่ผมแก้มาก็เล่นได้ 4-5 ชั่วโมงได้ไม่เจออาการ Crash/Freeze อีกเลยครับ 🙂
English:
For english guys (if any), I found one potential workaround to solve the random crash/freeze issues on FFX HD Remaster on PC. I think the issue is around memory reach limit of 32 Bits process which is 2GB for application space(from totally 4GB – kernel and app/user space) which FFX has been built as 32 Bits app.
so once you configured the game with high graphic settings. it uses higher memory and might be able to trigger the issue more eaiser.
we can use the tool called “editbin.exe” which is the small utility to allow us to change the flag of the process which is “/largeaddressaware” that can help to incrase the app/user space of memory up to 3/4GB based on OS. but at least it will be higer than 2GB as system default.
you can find “editbin” from Visual Studio.
and after I applied this flag. I can play the game for 4-5 hours for 2 days without any crash. hope this can help for some.

