มาถึงตอนสุดท้ายของ SOLID กันแล้วนะครับ ตัวสุดท้ายตัว D ซึ่งมาจาก Dependency Inversion Principle (DIP) โดยที่ส่วนตัวผมเองนั้นคิดว่าหลักการข้อนี้ค่อนข้างมีประโยชน์และน่าจะเป็นที่รู้จักกันเยอะระดับนึงอยู่แล้วในโลกของการพัฒนา Software ช่วงนี้
DIP นั้นกล่าวว่า
Class ที่มีการเรียกใช้ Class อื่นๆนั้นไม่ควรที่จะมีการอ้างอิงถึงตัว Object ของ Class ที่ถูกเรียกตรงๆ แต่ควรที่จะเรียกผ่าน Interface หรือ Pointer ของ Base Class
เป้าหมายที่สำคัญของหลักการนี้เพื่อทำให้ Code นั้นมีการผูกติดกันให้น้อยที่สุดกับสิ่งที่เป็น Dependency ของ Class เรา
คำว่า Dependency ในกรณีนี้ก็คือ เช่น เรามี Class SmartPhone แล้วมี Data Member เป็น Object ที่สร้างจาก Class BluetoothDevice เช่น Code ตัวอย่างนี้
class BluetoothDevice {
public connect(){ /* do low level network tasks */}
public scan(){}
}
class SmartPhone {
private bt : BluetoothDevice; // มีการถือ object BluetoothDevice ใน Class
public init(){
this.bt = new BluetoothDevice(); // มีการสร้าง Object ใน Class
}
public connectBluetooth(){
this.bt.connect();
}
}
จะเห็นว่า Code ข้างต้นนี้ออกแบบได้ถูกหลัก Single Responsibility แล้วเพราะเราทำการแยก Class ของ SmartPhone และ BluetoothDevice ออกจากกันตามหน้าที่ 🙂 ตามรูปด้านล่าง
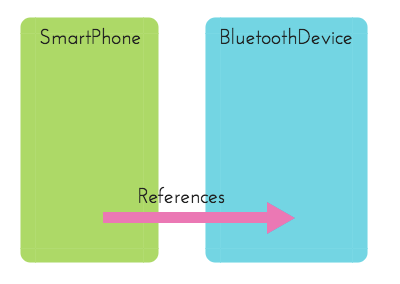
Refactor
แต่ถึงอย่างนั้นด้วย DIP เราจะทำให้ Class นี้มี Design ที่ดีขึ้นไปอีกโดยที่เราจะใช้ Interface เป็นตัวกลางในการ Reference เช่นรูปด้านล่างนี้
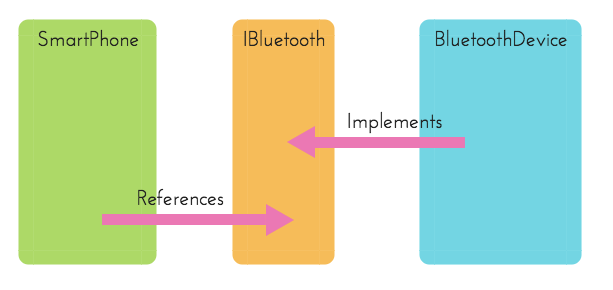
ดังนั้น Code ที่ทำการ Refactor โดยการ Inversion แล้วก็จะมีหน้าตาแบบนี้แทนครับ
interface IBluetooth {
connect();
scan();
}
class BluetoothDevice implements IBluetooth { // class นี้ทำการ implements interface
public connect(){
/* do low level network tasks */
console.log('bluetooth connect');
}
public scan(){}
}
class SmartPhone {
private bt : IBluetooth; // อ้างถึง Bluetooth ผ่าน Interface ไม่ใช่ Object
public init(bt : IBluetooth){ // มีการรับ Object ที่มี Interface IBluetooth เป็น Parameter
this.bt = bt;
}
public connectBluetooth(){
this.bt.connect();
}
}
จาก Code ด้านบนนี้จะเห็นว่า Class SmartPhone นั้นไม่ได้มีการอ้างอิงไปถึง Object ของ Class BluetoothDevice ตรงๆแล้วแต่จะใช้ Interface แทนครับ ทำให้การที่จะเรียกใช้ Method ที่ถูกต้องของ BluetoothDevice นั้นจะต้องมีการสร้าง Instance ของมันให้ถูก
.
.
Code ของฝั่งที่จะสร้าง Object หรือ Instance จาก Class SmartPhone จึงต้องเปลี่ยนไปเป็นเช่นนี้
let sp = new SmartPhone();
sp.init(new BluetoothDevice()); // ต้องสร้าง Object ของ BluetoothDevice ส่งไปให้
sp.connectBluetooth();
ซึ่งการทำการส่ง Object ที่เป็น Dependency ของอีก Class นึงเข้าไปแบบนี้คือการทำสิ่งที่เรียกว่า Dependency Injection ( DI ) นั่นเอง
.
Testable Code
ข้อดีที่เราจะได้รับจากการทำ DIP ก็คือการทำให้ Code ของเรานั้น Unit Test ได้ง่ายขึ้น
ลองคิดดูครับว่าถ้า Class BluetoothDevice ตัวจริงนั้นต้องไปต่อ Network จริงๆ แล้วเราจะเขียน Unit Test ของ Class SmartPhone ได้ยังไง
.
การทำ DIP นั้นจะทำให้เราสามารถ Inject Mock Dependency ลงไปได้เช่นดังตัวอย่างในรูปนี้
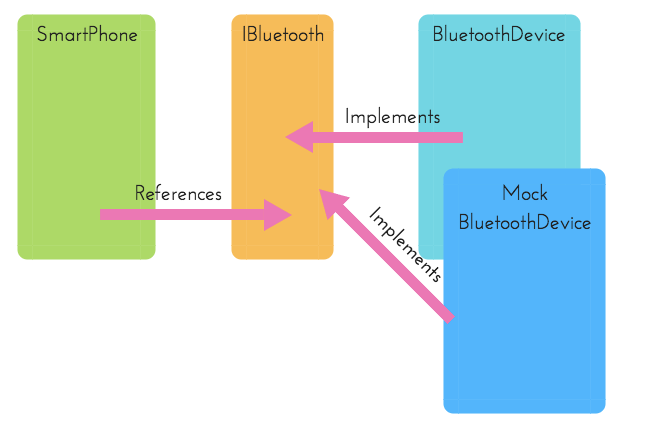
class MockBluetoothDevice implements IBluetooth {
public connect(){
console.log('just mock connect');
}
public scan(){
console.log('just mock scan');
}
}
Code ตอนเขียน UniTest
let sptest = new SmartPhone();
sptest.init(new MockBluetoothDevice()); // ส่งตัวปลอม(Mock) ของ BluetoothDevice ไป
sptest.connectBluetooth(); // ไม่ต้องไปต่อ Network จริงๆ
ก็จะเห็นว่า DIP นั้นช่วยทำให้ Code เราเขียน Test ได้ง่ายขึ้น แต่ทั้งนี้ทั้งนั้นทุกวันนี้เราจะเห็นว่ามี Framework ที่ช่วยทำ Dependency Injection มากมายเลยนะครับ แต่ผมอยากให้ทุกคนทราบกันว่านี่คือเบื้องหลังของมันรวมถึงที่มาที่ไปด้วย
เอาล่ะ มาถึงตรงนี้เป็นอันว่าจบหลักสูตร SOLID กันแล้วนะครับ สำหรับคนที่คิดว่ามันเยอะไปสำหรับ 5 หลักนี้ ผมก็คงแนะนำให้ทบทวน 2 ตัว คือ S กับ D ละกันครับ 🙂 และหวังว่าซีรี่ย์นี่จะเป็นประโยชน์กับหลายๆคนนะครับ
SOLID The Series: