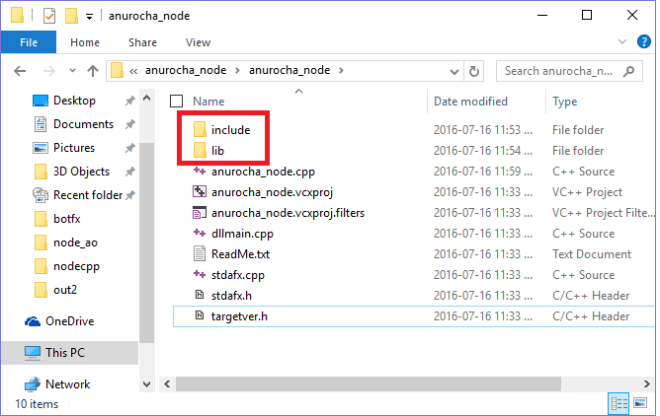
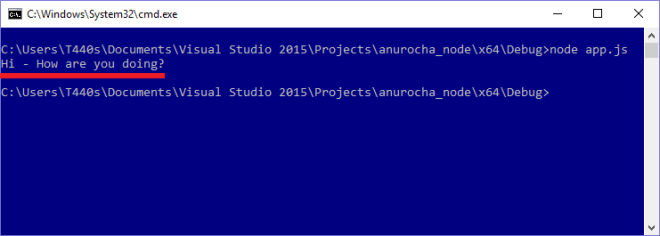
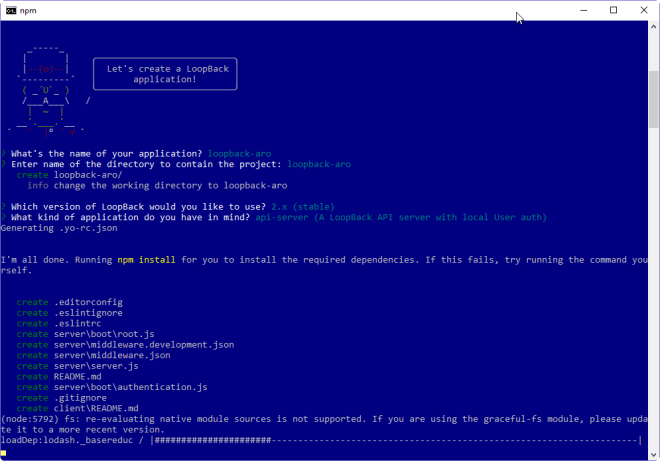
จากความเดิมตอนที่แล้วผมเคยเขียนเรื่องการสร้าง Node.js Module ด้วย C++ มาทีนึงแล้ว แต่ถึงอย่างนั้นถ้าเรา
– มี C++ Library อยู่แล้วล่ะ
– หรืออยากทำให้ Node สามารถเรียกใช้งานพวก System API โดยที่ไม่อยากศึกษาการเขียน Node Module แบบ Native
ผมก็ไปเจอว่ามี Community ที่ได้พัฒนา Framework มาตัวนึงซึ่งวันนี้เราจะมาพูดถึงกัน นั่นก็คือ Node-ffi ซึ่งย่อมาจาก Foreign Function Interface
Node-ffi นั้นเป็น Module ที่ทำหน้าที่เป็นตัวกลางในการทำการติดต่อระหว่าง JavaScript Code ไปที่ C++ Library โดยที่เราไม่ต้องเขียน Native Module เอง ประมาณรูป Diagram ด้านล่างครับ
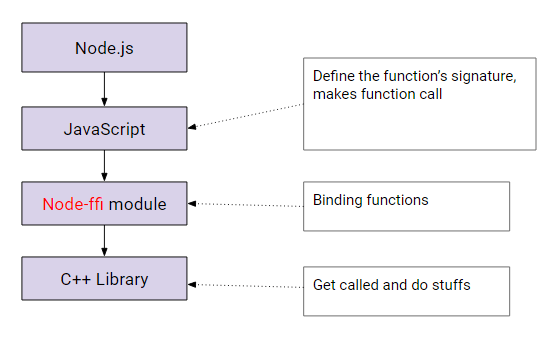
เรามาลองดูการใช้งานกันดีกว่าครับ
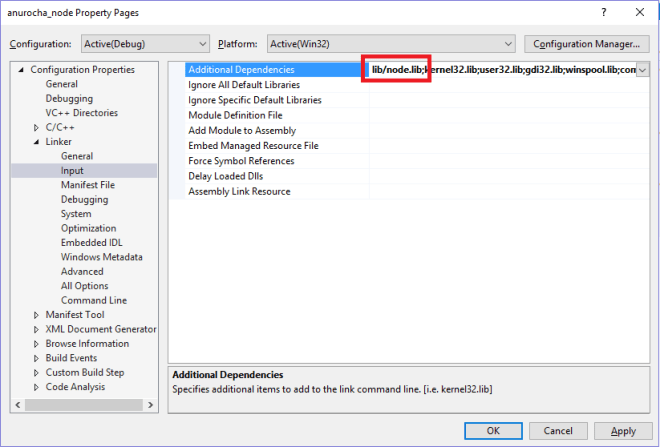
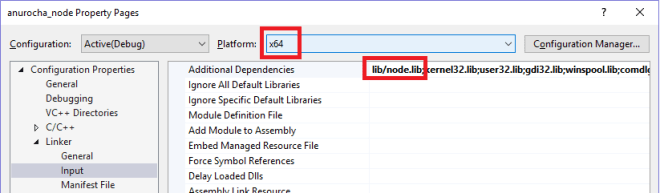
ก่อนอื่นเรามี C++ Library ที่เป็น DLL ที่ต้องการจะเรียก ซึ่งผมลองเขียนมาแบบง่ายๆคือ dll ที่มี function ในการ ดึงค่า Version ของ OS
extern "C" DLLIMPORT int getVersion()
{
DWORD dwVer = ::GetVersion();
DWORD majorVer = (DWORD)(LOBYTE(LOWORD(dwVer)));
return majorVer;
};
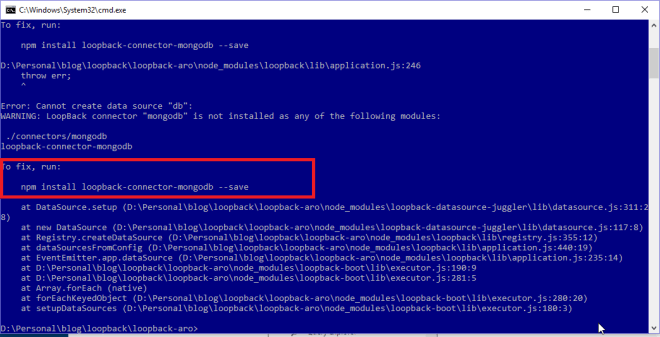
ซึ่ง API ::GetVersion นั้นเป็นของ Windows SDK ครับ ซึ่งสำหรับฝั่ง C++ ผมได้ทำการ Compile ออกมาเป็น dll ชื่อ dev.dll
ทีนี้มาลองดูส่วนที่สำคัญของเราก็คือฝั่ง JavaScript
var ffi = require('ffi');
var devModule = ffi.Library('dev', {
'getVersion': [ 'int', [] ]
});
console.log('Windows version : ' + devModule.getVersion());
จาก Code นี้ก็มี 3 ส่วนหลักๆครับ
- require module ‘ffi’
- ประกาศการทำ function binding
ffi.Library('dev', { 'getVersion': [ 'int', [] ]2.1 ทำการ binding กับไฟล์ library ชื่อ dev.dll
2.2 ทำการ binding กับ function ชื่อ getVersion โดยมี ‘int’ เป็น Type ของ Return Value
2.3 Function getVersion นี้ไม่มี parameter เลยใส่เป็น [] - เรียกใช้ ffi ด้วย devModule.getVersion()
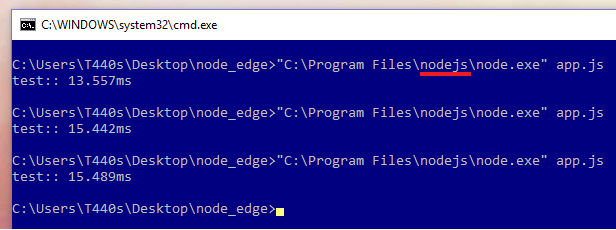
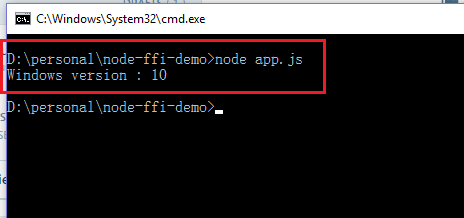
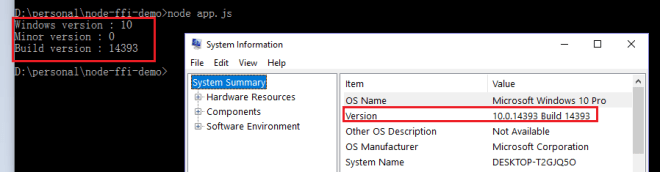
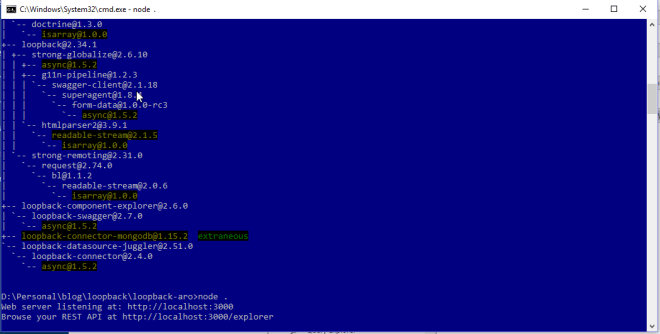
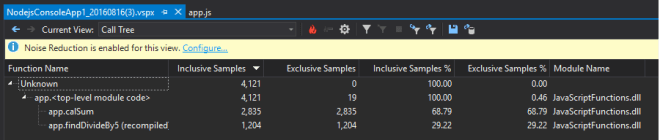
ผลของการรันก็เป็นดังนี้ครับคือได้ค่า ’10’ มาจาก getVersion
นอกจากนี้เรายังสามารถประกาศการทำ binding ทีละหลายๆ function ก็ได้เหมือนกันครับ(ขออนุญาติไม่โชว์ Code ฝั่ง C++ ที่เขียนเพิ่มเพื่อดึงค่า Minor,Build Version) เช่น
var devModule = ffi.Library('dev', {
'getVersion': [ 'int', [] ] ,
'getMinorVersion' : [ 'int', [] ],
'getBuildVersion' : [ 'int', [] ]
});
console.log('Windows version : ' + devModule.getVersion());
console.log('Minor version : ' + devModule.getMinorVersion());
console.log('Build version : ' + devModule.getBuildVersion());
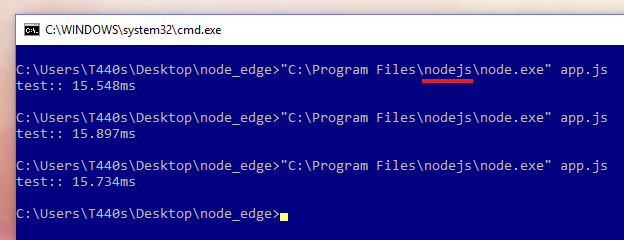
ผลการรันก็ดูดีครับและตรงกับ System Info จริงๆนะ 🙂
สรุป : node-ffi น่าจะเป็นอีกหนึ่งทางเลือกสำหรับคนที่เขียน Node.Js ด้วย Context บางอย่างที่ต้องติดต่อกับ System หรือ OS ระดับ Low Level (เหมือนผม..) โดยที่เรานั้นไม่ต้องมาการเรียนรู้การเขียน Node Module แบบ Native ที่อาจจะมีความซับซ้อนกว่าทั้งในแง่การทำ Mapping พวก Data Types รวมถึงการมานั่งศึกษา V8 API ซึ่งผมคิดว่า node-ffi อาจจะมีผลกระทบกับ Performance ในการ call function บ้าง แต่ผมก็ยังไม่ได้ลองวัด ทั้งนี้ทั้งนั้นใครมีข้อมูลเพิ่มก็แชร์กันได้ครับ





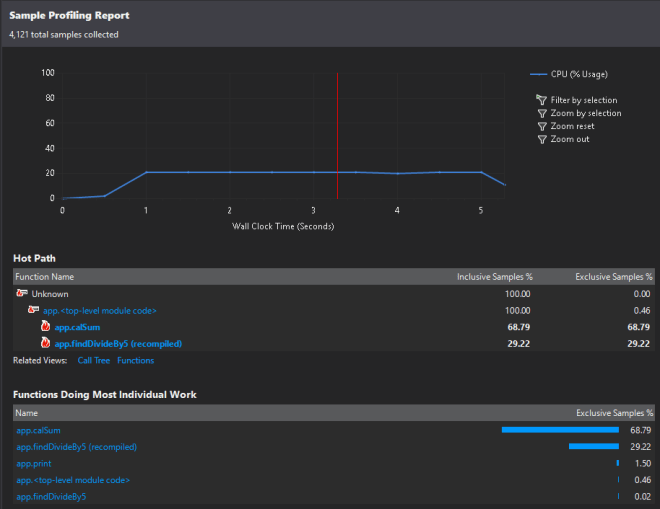
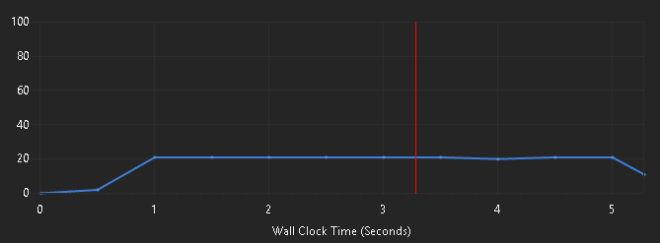




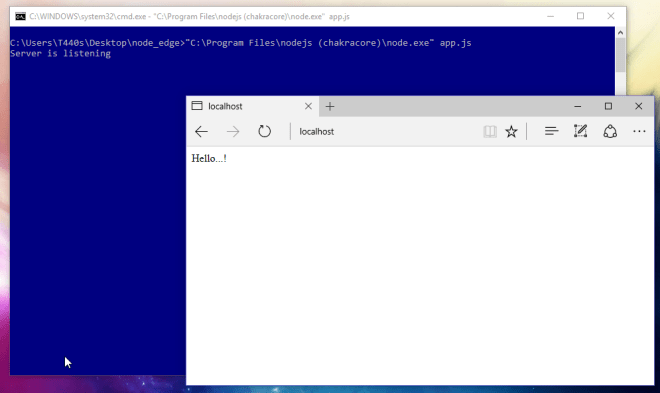
 ลองรันกับ Node.js (V8) ปกติก็พบว่า…. 15ms ช้ากว่า Chakra เกือบ 3 เท่า…
ลองรันกับ Node.js (V8) ปกติก็พบว่า…. 15ms ช้ากว่า Chakra เกือบ 3 เท่า…